

Unearthing the past

This weekend I received an email from Google Scholar that a paper of mine had been cited in a new piece of research.

Now, for some of you, this might be quite routine, but I’ve only ever written one paper and it isn’t exactly the most academic of works. Worse still, on reading the citation and the reference was in regard to my approach being dismissed <sad_face_emoji>.
Ok, let’s put a bit of context around this.
At the time I wrote the paper, I had been spending a fair bit of time tracking a number of malware variants, each solely used by just one threat group, but all making use of HTTP for command and control. Truth be told, the formulaic structure of the HTTP comms made it relatively trivial to write a signature for, but for every variant, there was a new signature and it didn’t seem to scale well. Worst still, newer variants weren’t necessarily caught by the old signatures, so there was always a bit of latency until they could be detected via some other means for a new signature to be written.
Personally, I’ve been always been a big subscriber to the then recently published Pyramid of Pain by David Bianco. At the core of the framework is that you should try and elevate your detection capability away from very dynamic and transient identifiers such as IP addresses and Domains (or worse still, File Hashes), instead trying to detect more general tradecraft.

So the question here was could I find a way to more generically detect the use of HTTP communications by malware.
But why HTTP? Firstly, many HTTP protocol libraries already exist that malware developers could simply plug-and-play, rather than having to completely re-write code from scratch1. Secondly, whether it’s the simple fact HTTP is over TCP port 80, or a more protocol-aware proxy, HTTP comms are one of the few types of traffic that are allowed to egress the network relatively unchecked – even one that’s pretty locked down. Lastly, if you’re the sort of organisation that does inspect traffic, masquerading as one of the more common protocols you’d expect to see egressing the network is a good way of simply hiding in the noise!
A spelling test for network traffic
Looking at the HTTP implementation in the samples I had to hand, there were some general mistakes that we could possibly look for. Evidence of typos in some of the fields, spelling errors, extraneous spaces or field delimiters were common – but none that were particularly consistent, nor did every sample have an error. The original RFC was also worth a look, but the areas of non-compliance were largely the same typo errors as before.
Given the root of the question was really about being able to tell the difference between legitimate HTTP activity and that used by malware, it was probably worth a look at what legitimate activity looked like! One thing that began to stand out was each browser family did HTTP ever so slightly differently, with the first I noticed being an artefact of the case sensitivity “battle” between Microsoft and *nix systems:
Connection: Keep-Alive
vs
Connection: keep-alive
At the very least, this tells us that its potentially possible to fingerprint the browser being used. A little bit of research later surfaced a fingerprinting tool known as p0f2 that, amongst other things, will attempt to fingerprint the OS based on slight variations in TCP configurations - but it also looked at HTTP traffic as well.
In essence, the RFC only tells you how to structure HTTP Header fields, but makes no real distinction (other than a few exceptions) for those writing the underlying code for a browser on what you should or shouldn’t include, including in what order. P0f looks for those little deviations.
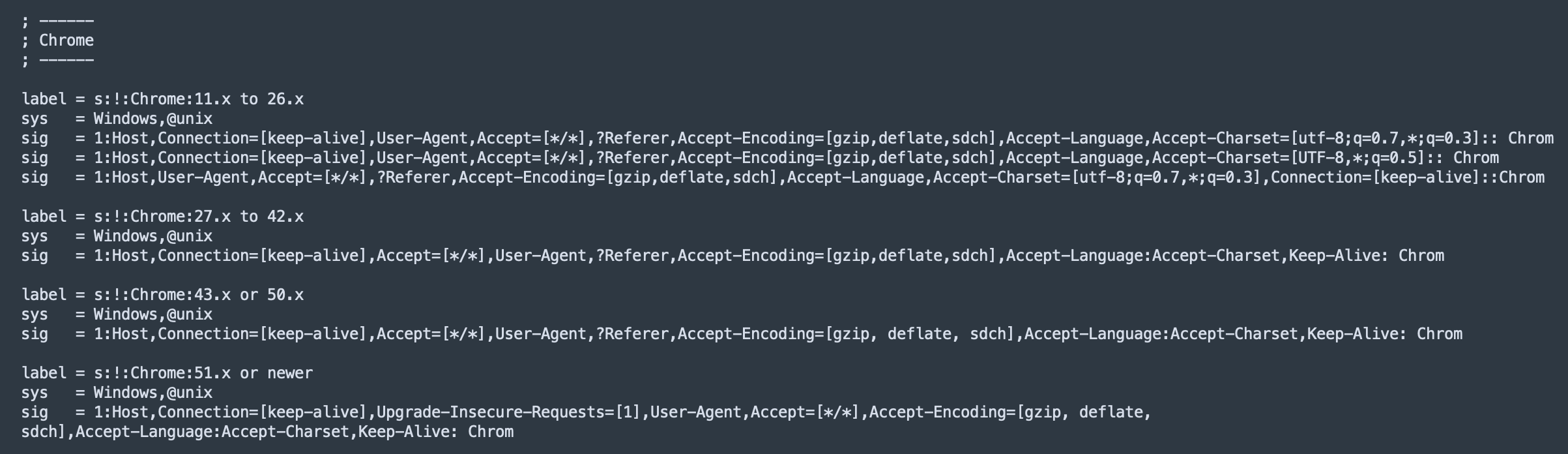
Ok, so we now had something that could fairly reliably tell me what the browser was - but that still isn’t quite the same as telling if it was malicious.
The HTTP lie detector
As part of the use of HTTP, one of the critical fields is User-Agent. This is a text string used to identify the browser being used (irregardless of fingerprinting techniques) for web-servers to be able to return the right sort of content (in reality, this has become more about the distinction between mobile and desktop browsers). This is yet another field that malware attempts to mimic, often using a hard-coded string taken from legitimate browser.
With p0f, I’ve got the opportunity to put the User-Agent claim to the test. If it says it’s Internet Explorer, I’ve probably got a good chance of spotting when malware is making only a loose attempt to hide in the noise. In essence, a HTTP Lie Detector. And if it’s lying, its probably malware.

Dismissing the approach
The year I wrote the paper was, coincidentally, the year Darktrace was founded3, now 10 years ago. This is a company that takes pretty much the same approach to detecting traffic without needing a constant feed of “what does bad look like” to know that something shouldn’t belong there. Essentially, by understanding what the normal traffic looks like and flagging activity that isn’t as expected.
So why was my approach dismissed? Given the success of Darktrace4, I certainly don’t believe the fundamental concept is flawed. The challenge from the author was that my implementation was from a rules and signature-based approach - and actually, I’d argue he’s right! In the paper, I proposed a number of SNORT rules for the approach – but largely as it was the prevailing detection technology at the time and the paper was for a vocational qualification rather than an academic research paper.
You can read the paper “HTTP Header Heuristics for Malware Detection” here:
https://www.sans.org/white-papers/34460/
… and for completeness, if you want the latter paper that cites me, you can read it here: https://arxiv.org/pdf/2306.03733.pdf
P0f, written by Michael Zalewski - https://lcamtuf.coredump.cx/p0f3/
Whilst the paper was published in 2014, it was written in over the 2nd half of 2013. Actual publish date was January 2nd 2014… so close enough, even for the pedants.
DISCLAIMER - I am currently gainfully employed by Darktrace